Why NON-LINEAR Activation functions in Hidden Layer
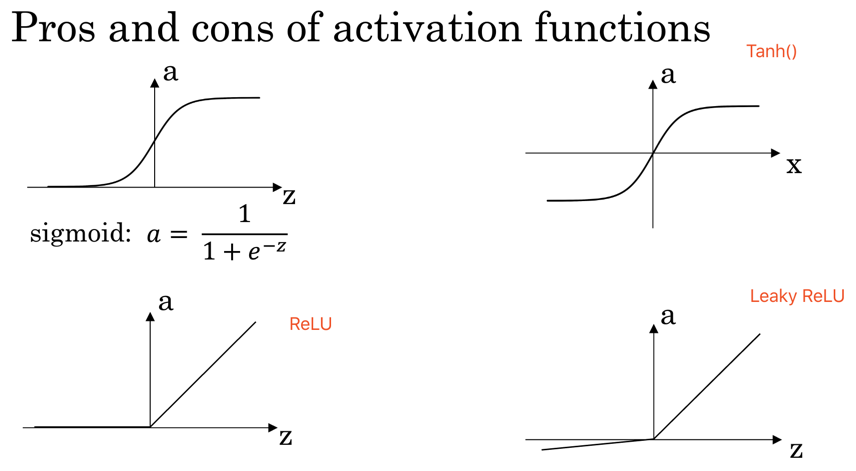
| Activate Function | Scope | Formular | ||
|---|---|---|---|---|
| ReLU | Most popular in hidden layer of NN | [0,+∞] | Max(0,z) | 比Tanh & Sigmod快得多,bez ReLU 没有斜率接近0时减慢学习速度; |
| Leaky ReLU | Hidden Layer | Max(0.01z,z) | ||
| Tanh | Hidden Layer | [-1,1] | 相当于sigmod下移 | |
| Sigmoid | useless or output layer | (0,1) | 最多仅用于输出层 |
noted: Tanh =
AndrewNG 在3.7 lesson ,解释了为什么要NON-LINEAR activate function
如果在深层网络中,在hidden layer一直用线性激活函数,那跟没有hidden layer 效果一样,因为多个linear function整合起来是一个线性函数是一样的效果,除了一些有关压缩的极少情况。所以一般大多都用non-linear function in Hidden layer .
隐藏层多数用非线性activate function,这样才会收敛