为什么特征工程和特征选择值得讨论
作者:江嘉键
首先,追本溯源,为什么特征工程和特征选择值得讨论?在实际的数据分析和建模中,我们通常要面对两种情况:
- 数据集中已有的特征变量不够多,或者已有的特征变量不足以充分表征数据的特点;
- 我们拥有大量的特征,需要判断出哪些是相关特征,哪些是不相关特征。
特征工程解决的是第一个问题,而特征选择解决的是第二个问题。
对于特征工程来说,它的的难点在于找到好的思路,来产生能够表征数据特点的新特征变量;
而特征选择的难点则在于,其本质是一个复杂的组合优化问题(combinatorial optimization)。例如,如果有 30 个特征变量,当我们进行建模的时候,每个特征变量有两种可能的状态:“保留”和“被剔除”。那么,这组特征维度的状态集合中的元素个数就是。更一般地,如果我们有 N 个特征变量,则特征变量的状态集合中的元素个数就是
。因此,从算法角度讲,通过穷举的方式进行求解的时间复杂度是指数级的(O(
))。当 N 足够大时,特征筛选将会耗费大量的时间和计算资源(图1)。在实际应用中,为了减少运算量,目前特征子集的搜索策略大都采用贪心算法(greedy algorithm),其核心思想是在每一步选择中,都采纳当前条件下最好的选择,从而获得组合优化问题的近似最优解。
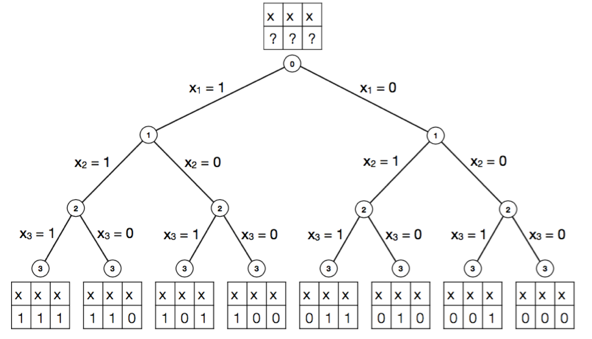
图1:通过穷举法求解特征选择问题的二叉树表示。状态集合中元素的个数随特征变量数目增加而呈现指数增长。
目前很多流行的机器学习的材料,都未能给出特征工程和特征选择的详细论述。其主要原因是,大部分机器学习算法有标准的推导过程,因而易于讲解。但是在很多实际问题中,寻找和筛选特征变量并没有普适的方法。 然而,特征工程和特征选择对于分析结果的影响,往往比之后的机器学习模型的选择更为重要。Coursera 上ML课程主讲老师 Andrew Ng 就曾经表示:“基本上,所谓机器学习应用,就是进行特征工程。”