refer to 深度学习原理与TensorFlow实践》学习笔记(一)
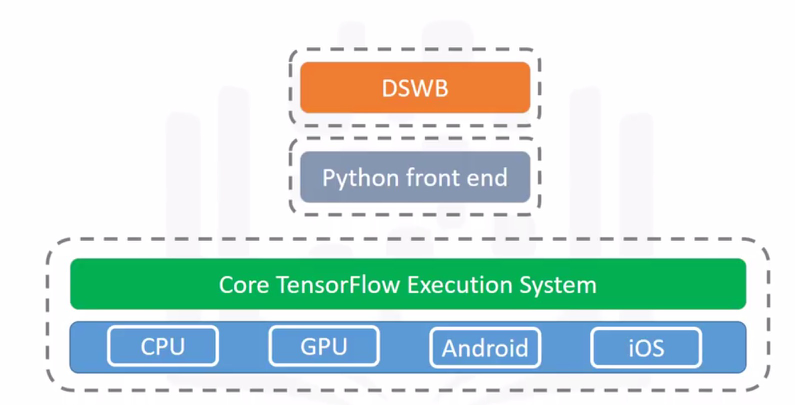
TensorFlow的设计目标
- 具有灵活的表达能力,能够快速实现各种算法模型
- 高执行性能,具备分布式扩展性(GPU集群训练)
- 跨平台可移植性
- 实验可复现性
- 支持快速产品化,模型可随时部署
TensorFlow的核心概念
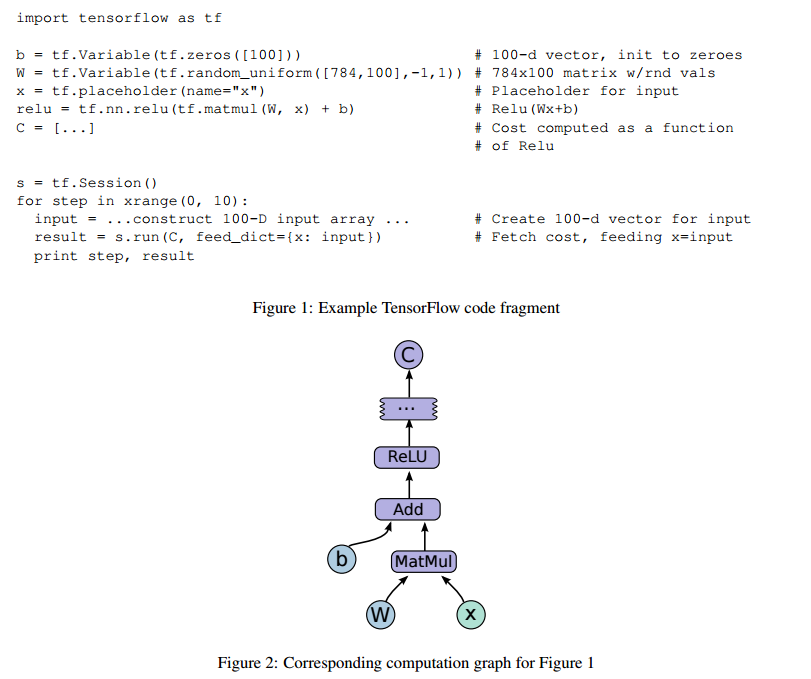
计算图(Dataflow Graph)与tensorflow的运行方式
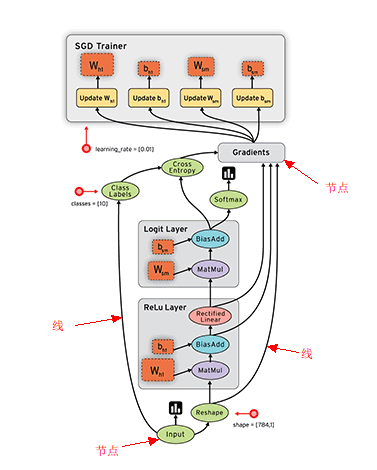
用有向图表示计算过程
边:Tensor(N维数组)
节点:算子Operations(数学计算)
张量 Tensor
高维数组,维数描述为阶,数值(scalar)是0阶梯,向量(vector)是1阶,矩阵(matrix)是2阶,以此类推
支持多种数据类型
Operations
主要是由Eigen矩阵计算库完成
支持多种运算

Variable & Placeholder
Variable 用于存储模型的权值,训练模型时,会更新这个它.
每次正向计算完成之后,根据BP算法调整权值,代入下一轮计算
Variable 必须要初始化.
Placeholder - 用来存储从外部模型来的数据 ,
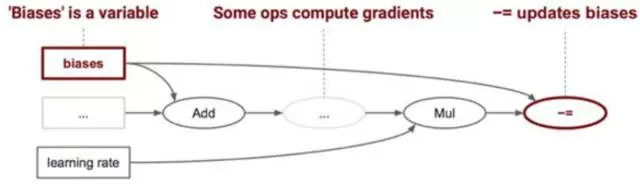
Session
构建计算图
多设备或分布式的节点布置
Session.run() 将图塞入device (CPU,GPU) 去执行。
with tf.Session() as sess:
result = sess.run(c)
print(result) # 用with 语句,可不用写 sess.close after complete the computation
- 编程结构

分布式架构
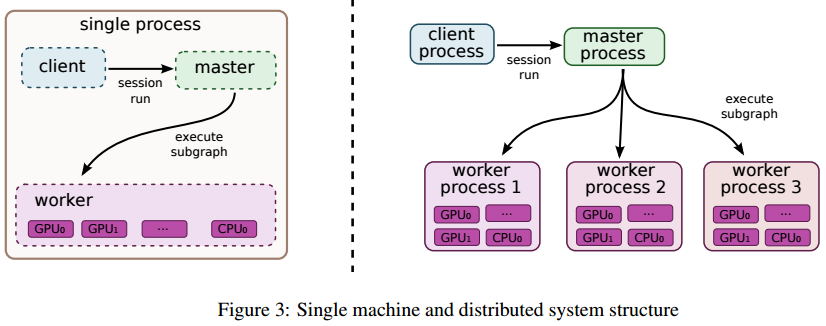
数据并行分布式
- 数据并行是最主要的分布式方式
- 将训练数据分成多个 partition,每个 replica 只负责一个 partition,每个partition包括多个batch
- 在每个replica中计算多个batch的loss和BP,得到权值更新Delta,但此时权值并未被更新
- 权值更新Delta被上传到中心化的 Parameter Server 上,由 Parameter Server 统一更新(计算多个batch的delta均值)并分发(在replica中更新权值)
- 值得注意的是 Parameter Server 并不是 Master,仅负责参数分发,不负责统一调度
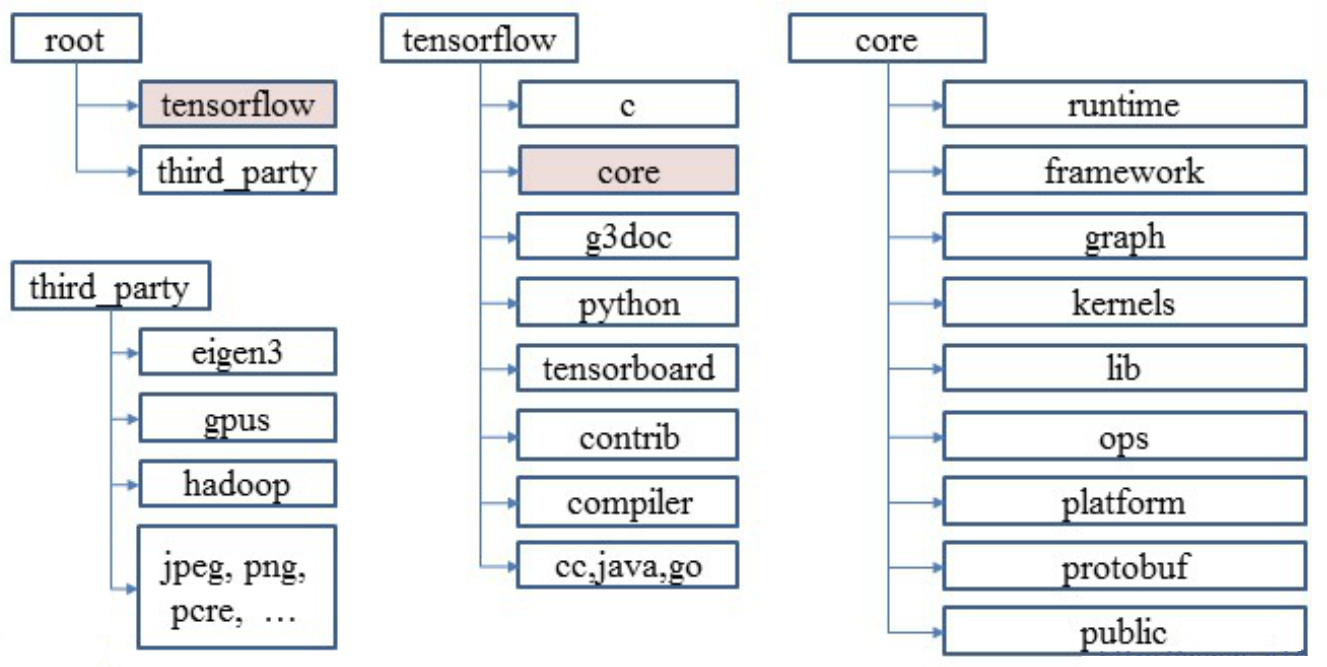
代码结构